机器学习可以根据 the amount and type of supervision they get during training,分成 Supervised learning,Unsupervised earning,Semi supervised learning,还有 Reinforcement learning。
参考书:《Hands-On Machine Learning with Scikit-Learn and TensorFlow》by Aurélien Géron
监管学习:Supervised Learning
在监管学习中,喂给算法的数据里包含着期望得到的结果,这些东西叫 Labels(标签)。比如一个邮件垃圾过滤系统,训练它的时候用的邮件数据带着标签,邮件实例的标签表示邮件是正常邮件,还是垃圾邮件。
常见的监管学习任务有 Classification(分类)。邮件垃圾过滤器得到一个邮件,会知道它的类别属于正常邮件还是垃圾邮件。
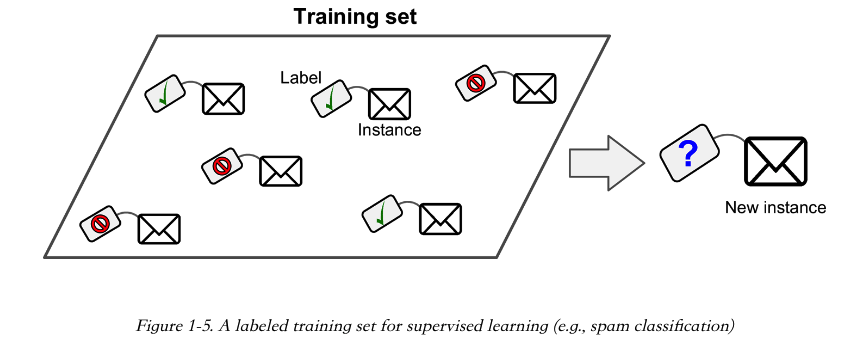
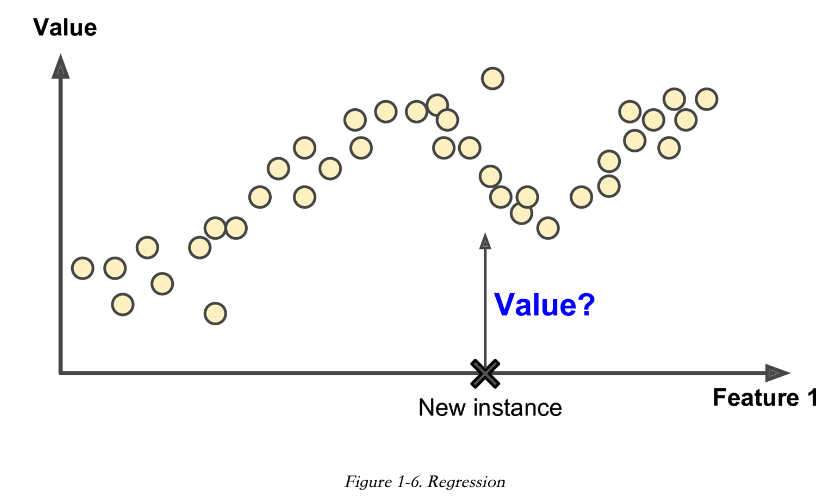
还有种常见的任务是预测目标值。比如一辆二手车,根据它的一些 Features(特征),比如里程,车龄,品牌等等来预测这辆车的价值。这种任务叫 Regression(回归),它是统计学里的概念。训练这种系统,你得提供很多汽车示例,包含他们的 Predictors(就是上面提到的 Features),还有 Labels,比如汽车的价格。
在机器学习中,Attribute(属性) 是一种数据类型,比如汽车的里程。Feature 根据语境有几种意思,一般它表示的就是:属性 + 值,比如 里程:15,000。 有时候这两个名词也会交替使用。
名词
- labels
- classification
- features
- regression
- attribute
注意有些回归算法也可以用作分类,反过来也是一样。比如 Logistic regression 这种算法经常用于分类,它可以输出给定类别的概率值,比如 20% 的可能这是个垃圾邮件。
监管机器学习算法
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines(SVMs)
- Decision Trees and Random Forests
- Neural networks
自信心在学习中的角色很重要,有时看到一个不懂的公式或名词,就开始怀疑自己的智商,同时伴随逃避。经常要试过几次以后才能继续下去,解开一个公式以后,开始建立信心,觉得能明白其它的公式。这时就可以继续学习了。
看到一些从来没有尝试过的东西,如果不懂,就认为自己不擅长。比如我看不懂图表,就觉得自己不擅长看图表。当我不再认为不是自己不擅长,只是没有耐心而已的时候,慢慢就可以开始看懂图表了。不擅长可能是个借口,不是真的不擅长,只是没有耐心。没努力试过,怎么就下结论说自己不擅长了呢。
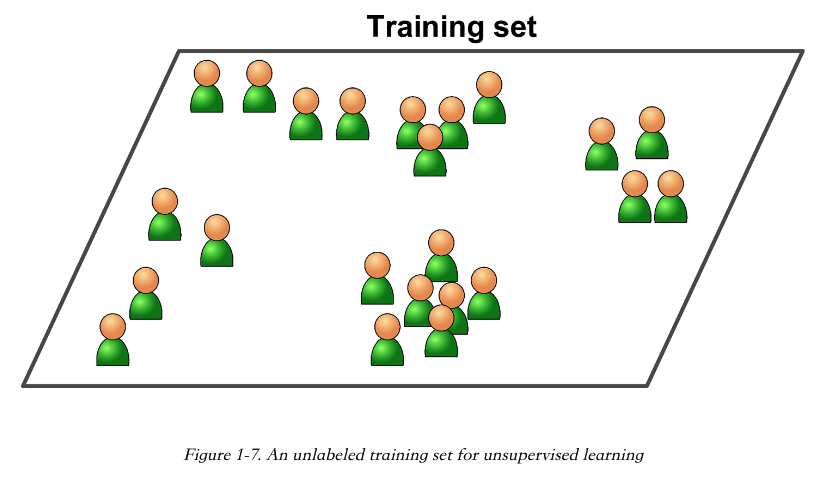
无监管学习:Unsupervised Learning
无监管机器学习用的 Training data(训练数据) 没有标签。系统会试着自学。
无监管机器学习算法
- Clustering
- k-Means
- Hierarchical Cluster Analysis(HCA)
- Expectation Maximization
- Visualization and dimensionality reduction
- Principal Component Analysis(PCA)
- Kernel PCA
- Locally-Linear Embedding(LLE)
- t-distributed Stochastic Neighbor Embedding(t-SNE)
- Association rule learning
- Apriori
- Eclat
你有很多关于你网站访客的数据。你可以使用 Clustering 算法试着把相似的访客分分组,算法会自己找到访客之间的关联。比如它可能会发现有 40% 的访客是男性,他们喜欢漫画,一般在晚上阅读你写的文章。有 20% 是年轻的科幻爱好者,经常在周末访问你的网站 ... 如果你使用 Hierarchical clustering 算法,你还可以把每个小组继续分割成更小的群组。
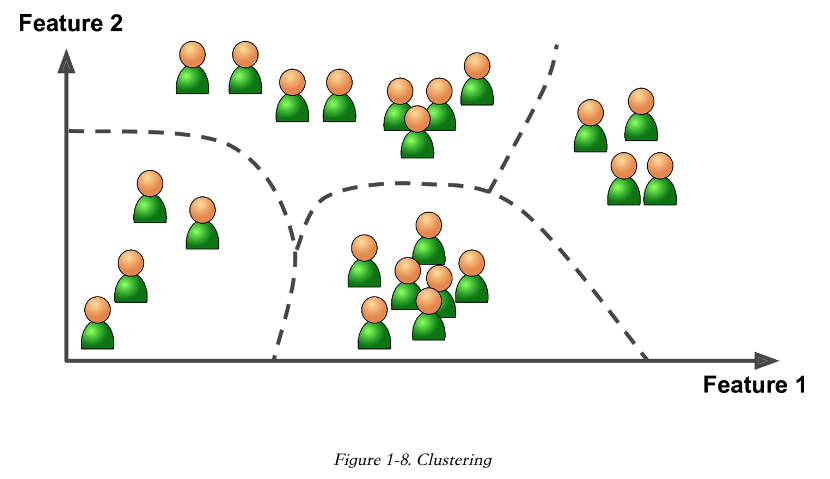
Visualization 算法,也是一种无监管学习算法。你可以喂给它大量复杂且无标签的数据,算法会给你输出数据的 2D 或 3D 的展示,它们可以很容易绘制成图像。这些算法会尽可能地保留数据的结构,这样你可以理解数据的组成,也有可能会发现一些未知的模式。
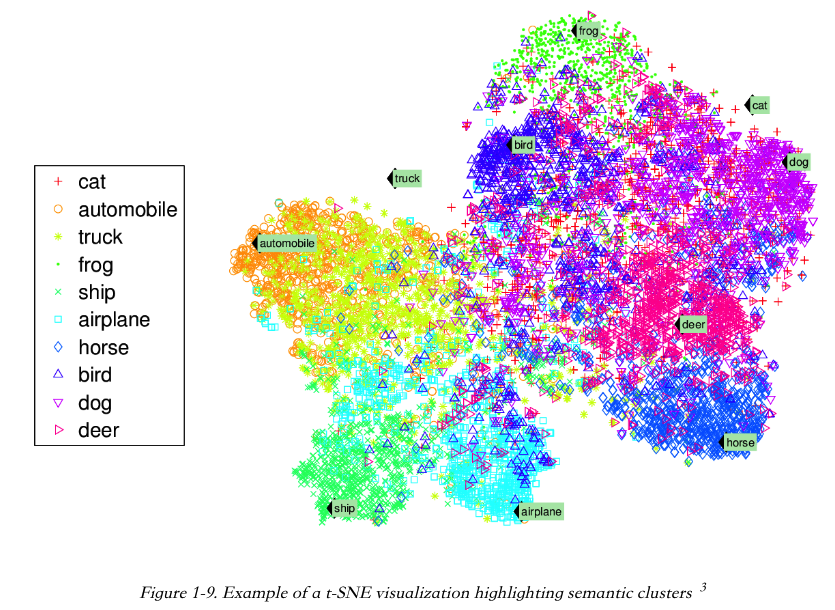
相关的任务是 Dimensionality reduction(降维),它的目标是在不丢失太多信息的情况下去简化数据。降维的一种方法就是把几个相关的特征合并成一个。比如,一辆车的里程可能跟它的车龄相关,所以降维算法就会把它们合并成一个表示汽车磨损的特征。这个叫做 Feature extraction(特征提取)。
在把数据喂给其它机器学习算法之前,可以先用 Dimensionality reduction 算法把数据降维,这样运行会更快,数据占用的磁盘与内存更小,有时候效果也会更好。
无监管学习还有个重要的任务是 Anomaly detection(反常检测)。比如,检测信用卡的非正常交易来防止欺诈。把数据集里的 Outliers(极端值) 去掉以后再把数据喂给其它的学习算法。系统用正常的数据实例训练,当它看到新实例,它能判断这个新实例是正常的,还是个 Anomaly (异常,反常)。

还有个常见的无监管任务是 Association rule learning,它的目标是挖掘大量数据,发现属性(Attribute)之间的关联。假设你有个超市,用 Association rule 处理你的销售数据,你发现了大家买烧烤酱还有薯片的同时经常还会买些牛排。这时候,你可以把这些东西摆的近一些。
机器学习


