Clustering,聚类,就是把一组数据分成不同的类别,这个类别也叫 Cluster,也就是簇。聚类是一种常用的数据挖掘与分析技术,它可以把相似的内容聚集到一个类别里,可以再配合一些数据可视化技术展示聚类后的数据,这样你可以发现数据里隐含的一些信息。
做聚类的时候经常会用一种叫 k-means 的算法,我们可以把一组数据的嵌入交给这种算法去处理,它会帮我们规类数据。
先给项目安装一个包,在终端,项目所在目录的下面,执行 npm install 安装一个 ml-kmeans。完成以后回到项目,在项目里面新建一个文件,名字是 clustering.mjs。
文件顶部导入几个包 ,一个 fs,来自 fs ,再导入 ml-kmeans 里的 kmenas。然后从当前目录 app.service.mjs 里面导入 openai。
下面可以用 let 声明一个数据,用一下 JSON.parse,处理的东西可以用一下 fs.readFileSync ,文件位置是当前目录 data 里的 posts_with_embedding.json。
声明一个 k ,让它的值等于 4,这个数字表示聚类的数量。再声明一个 results ,它的值是执行 kmeans 得到的结果 ,给它提供一组 embeddings ,用一下 data.map,返回项目里的 embedding 这个属性。kmenas 的第二个参数设置成 k。
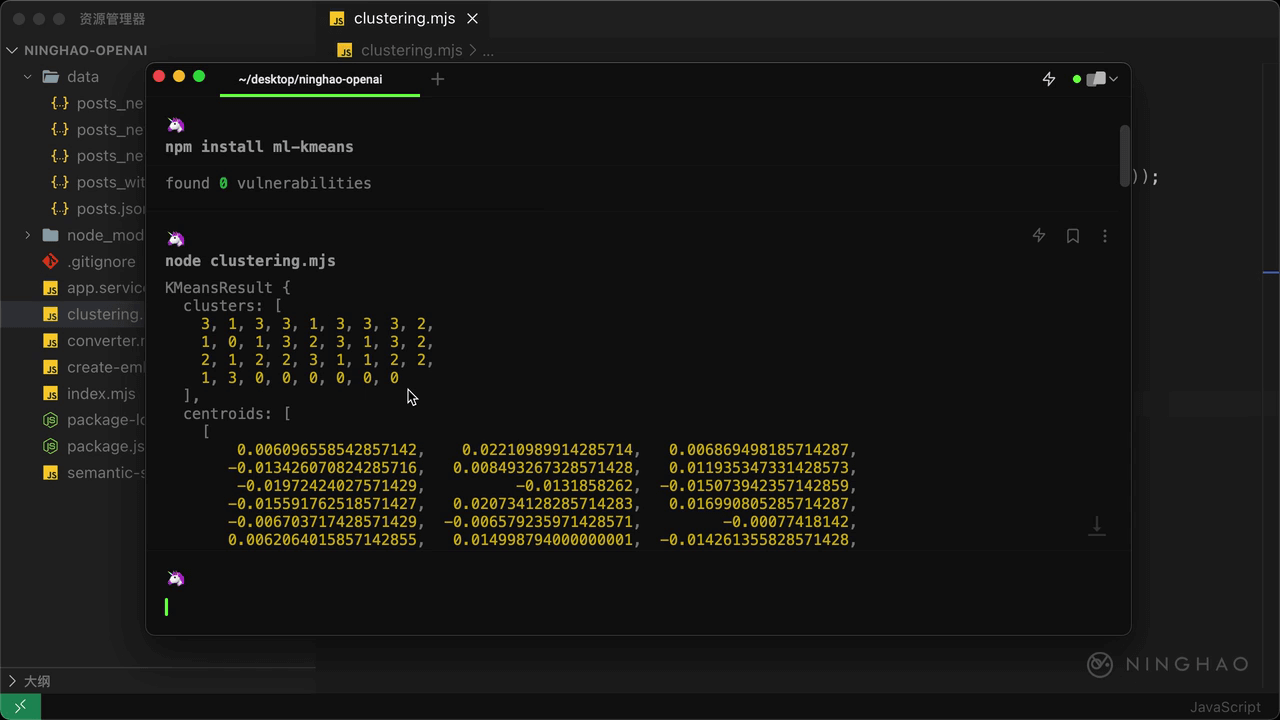
在控制台上输出 reuslts 检查一下。在终端,执行一下 node clustering.mjs,你会发现这个 results 里面,有一个 clusters 属性,它是一个数组,在这个数组里应该有 35 个内容项目,因为我交给 kmeans 处理的数据的数量就是 35 个,数组项目的值就是对应的某个数据的聚类的编号,你可以把它想成是数据的分类编号,其实就是一些索引号,因为我们要求创建四个聚类,所以索引号应该就是 0,1,2,3,正好是四个。
centroids 指的是中心点,或者叫质心,它表示的是聚类的中心。这里应该有四个项目,每个项目都是一个向量,这个向量就是某个对应的聚类的中心。使用这个 distance 方法,我们可以计算出数据与这个聚类中心点之间的距离,距离越近,说明数据与这个聚类越相关。
回到项目,解构一下这个 results,需要的是它里面的 clusters,centroids 还有一个 distance 方法。
下面重新设置一下 data 的值,等于 data,用一下 map,然后提供一个回调,两个参数,一个是 item,一个是 index。在这个函数里声明一个 clusterIndex,它的值是 clusters 方括号 index。这个 clusterIndex 指的是当前数据所属的聚类的编号。
返回一个对象,把 item 原有的东西放进来,然后添加一个 clusterIndex,再添加一个 distance 属性,它的值就是这个数据与数据所属类别的中心点的距离,可以用一下 distance 这个方法,第一个参数是 centroids 方括号 clusterIndex,第二个参数是 item.embedding。
然后用一个 for 循环输出内容,let i = 0, 1 < k ,i ++。每次循环的一开始,用 console.log 在控制台上输出一个换行符,然后是 Cluster 后面加上聚类编号,可以用这个 i 加上 1 。
然后声明一个 clusterData ,等于 data 用一下 filter ,提供一个回调,当前项目是 item,返回的项目是 item.clusterIndex 等于小 i 的项目。
下面再声明一个 clusterDataSample,等于 clusterData,用一下 map ,提供一个回调,当前项目是 item,返回项目里的 title属性的值,再用 slice 取 5 个项目,最后用 join 把它们合并成一个字符串,中间用逗号分隔开。
声明一个 response,等于 await ,用一下 openai 上面的 createCompletion ,请求使用 openai 的文本补全接口,要使用的 model 是 text-davinci-003,再添加一个 prompt ,一个字符模板,“这些内容有什么共同特点,请用一句话简要描述一下”,一个冒号,后面再加上 clusterDataSample 的值。把 temperature 设置成 0,max_tokens 设置成 256,top_p 是 1 。
然后用 console.log 在控制台上输出点内容,一个换行符,然后是摘要,冒号,后面是 response.data.choices 里的第一个项目里的 text 这个属性的值,接着用 replace 把这个字符串里的两个换行符替换成一个换行符,后面再加上两个换行符,然后是内容冒号。
最后再用一下 clusterData.forEach ,提供一个回调,当前项目是 item,在控制台上输出的东西是 item 里的 title,item 的 category 还有 item 里的 distance 。
在终端可以测试一下,执行 node clustering.mjs。这里会显示有四个 Cluster,里面有一段简单描述,然后是属于这个聚类下的内容列表。比如这里显示,第一堆儿内容是跟前端开发相关的内容,第二堆儿主要是跟 Node.js 相关的内容。
注意每次运行这个程序得到的聚类可能是不一样的。比如这次第一堆儿的内容主要是跟数据科学相关的内容。
